
Hindi and Tamil Question Answering
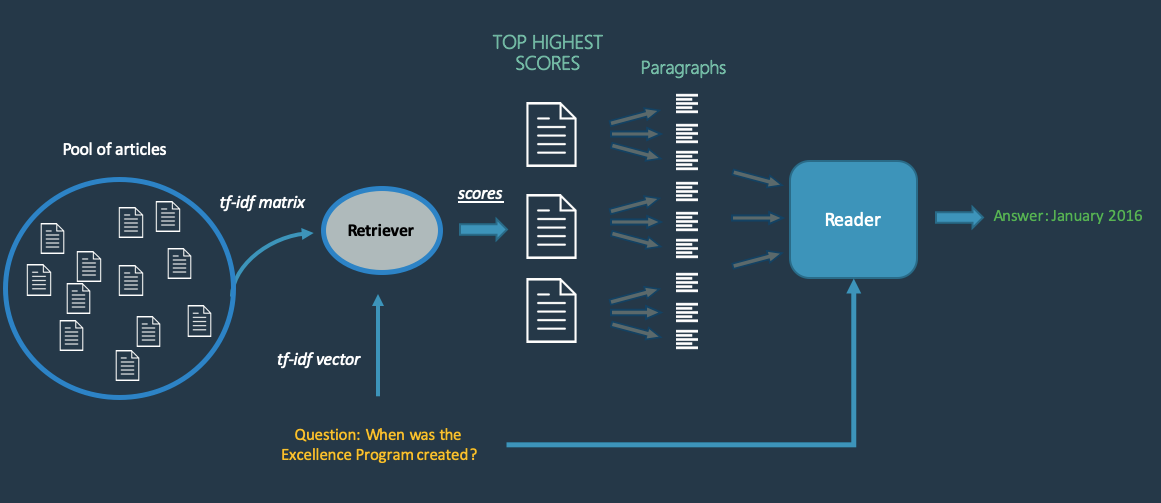
Context:
India, with its staggering population of nearly 1.4 billion people, is the second-most populous country globally. However, Indian languages, such as Hindi and Tamil, remain underrepresented on the web. Popular Natural Language Understanding (NLU) models often struggle with Indian languages, resulting in subpar user experiences for Indian web users. By harnessing the expertise of the Kaggle community and leveraging novel machine learning solutions, we can help Indian users fully utilize the web and overcome language barriers.
Problem: While predicting answers to questions is a common NLU task, it is less explored in Hindi and Tamil. Advancements in multilingual modeling require focused efforts to generate high-quality datasets and improve modeling techniques. Additionally, for languages with limited representation in public datasets, establishing trustworthy evaluations becomes challenging. This competition aims to address these gaps by providing a new question answering dataset called chaii-1. The dataset, covering Hindi and Tamil, was collected without translation and presents a realistic information-seeking task with questions crafted by expert native-speaking data annotators. Participants are encouraged to contribute additional datasets to drive future machine learning advancements for Indian languages.
Goal and Tasks:
In this competition, the objective is to predict answers to real questions based on Wikipedia articles. Participants will work with the chaii-1 dataset, a question answering dataset consisting of question-answer pairs in Hindi and Tamil. The dataset offers an opportunity to tackle information-seeking challenges without relying on translation. Participants will be provided with a baseline model and inference code to build upon.
Impact and Benefits:
Successful contributions to this competition will significantly enhance the performance of NLU models in Indian languages. The improved results have the potential to enhance the web experience for India’s vast population of nearly 1.4 billion people. Moreover, advancements in multilingual NLP achieved through this competition can extend beyond the languages specific to the competition. By participating, you not only contribute to the development of question answering capabilities in Hindi and Tamil, but you also contribute to the broader field of multilingual NLP.
Achievements:
In the “chaii - Hindi and Tamil Question Answering” competition hosted by Google India on Kaggle, I secured the 79th position globally, placing in the top 9% of participants worldwide. My approach involved training a “xlm roberta large-squad2” model using the provided dataset, enabling accurate answers to questions given any context in Tamil.
Through this competition, we strive to bridge the gap in NLU models for Indian languages, foster linguistic inclusivity, and enhance the accessibility of information for millions of Indian users.